
728x90
반응형

객체지향 프로그래밍(OOP)
개요
- Object Oriented Programming
- Java, Python, C++ 이 OOP에 해당된다.
- 재사용 하기 편하게, 확장성이 좋게 만든다.

- 캡슐화
- 캡슐 안의 가루약을 보호하기 위함.
- 섭취량 조절
- 1차적인 보안의 목적 : 외부에서는 참조되어지지 않게, 사용하지 못하게, 볼 수 없게 만듬
- 부품화시켜서 하나의 캡슐(부품)으로 만듬. 모듈화시킴.
- 코드의 분리를 통해 유지보수 및 재사용성을 높임.
- 상속
- 공통된 코드를 사용하게 하기 위해서, 부모 클래스의 기능들을 자식 클래스에서도 사용할 수 있게함.
- 중복 코드 방지
- 모듈들의 연관관계 형성
- 다형성
- 여러개의 형태를 띈다.
- 메서드, 변수에서 볼 수 있다.
- 추상화
- 스케치 개념 : 스케치(뼈대)를 만들고 디테일을 잡는 것.
- 대략적으로 정할 수 있는 것들, 공통된 특징을 뽑아서 미리 만들어 놓는 것.
- 추상 클래스, 인터페이스
OOP의 장단점

- 절차 지향(C언어) vs 객체 지향
- 절차 지향에서도 어느 정도의 모듈화(함수화)를 하겠지만, 객체 지향가 더 재사용성, 유지보수가 원활하다.
- 절차 지향이 객체 지향보다 속도가 빠르다.
클래스
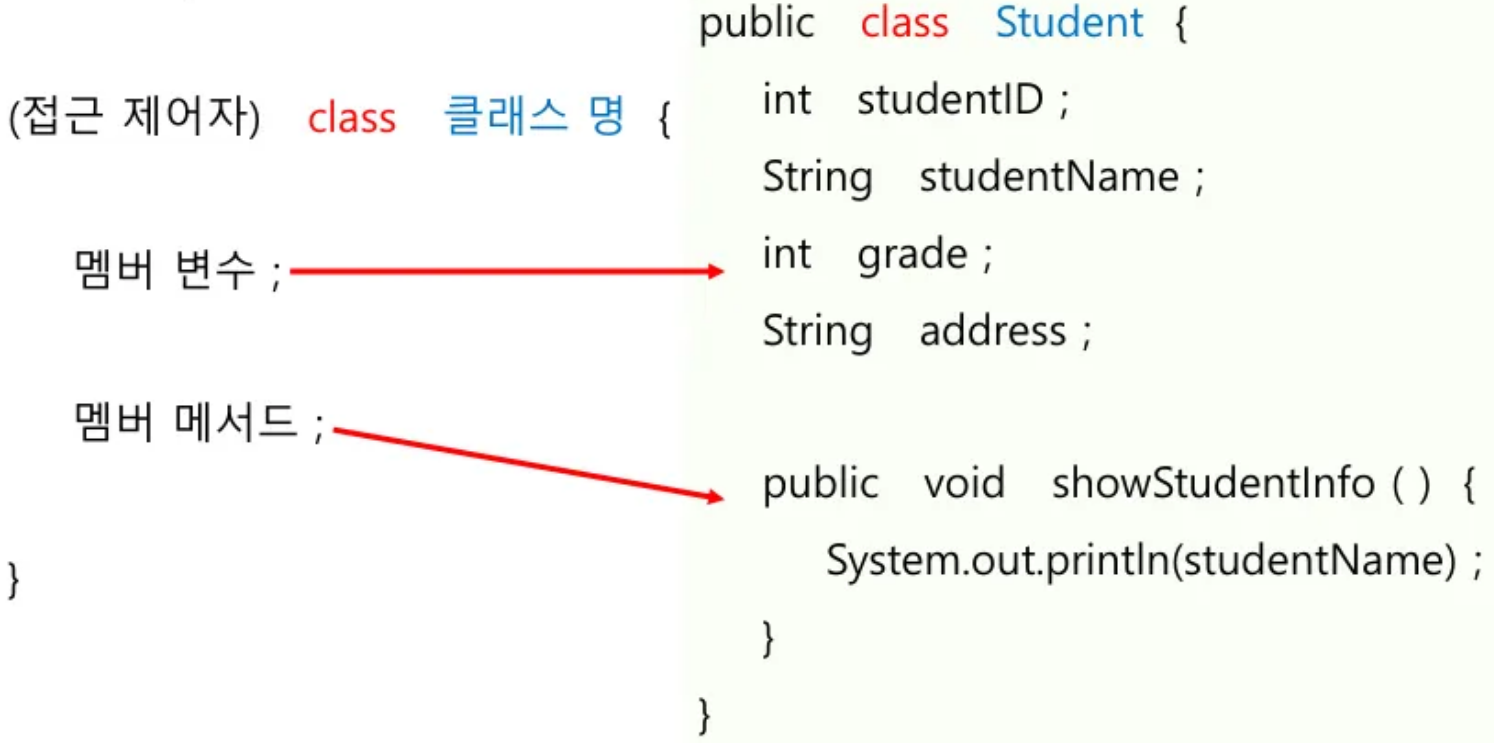
(접근제어자 : public, private 등등)
public class Student {
int studentID; // 4 개의 멤버 변수
String studentName;
int grade;
String address;
public void showStudentInfo () { // 멤버 메서드
System.out.println(studentName);
}
}
- 클래스 내의 구성 요소
- 멤버 변수
- 필드, 속성이라고도 불린다.
- 상황에 따라 인스턴스 변수라고도 불린다.
- 멤버 메서드
- 행동, 동작을 처리.
- 멤버 변수
- 멤버 변수, 인스턴스 변수, 클래스 변수 등의 차이
- 1. 멤버 변수
- 멤버 변수는 클래스 안에 선언된 변수를 말하며, 클래스의 속성을 정의합니다.
- 멤버 변수는 클래스 전체에서 접근할 수 있습니다.
- 멤버 변수는 두 가지로 나눌 수 있어요:
- 인스턴스 변수: 객체(인스턴스)마다 따로 저장되는 변수입니다. 객체가 생성될 때마다 새로운 값이 할당됩니다.
- 예: this.name = "John"; 같은 형태로 객체에 따라 다르게 저장되는 변수.
- 클래스 변수(정적 변수): 클래스 전체에서 공유되는 변수입니다. 클래스의 모든 인스턴스가 동일한 값을 공유합니다.
- static 키워드를 사용해 선언합니다. 예를 들어, static int count = 0;는 모든 인스턴스가 같은 count 값을 공유합니다.
- 인스턴스 변수: 객체(인스턴스)마다 따로 저장되는 변수입니다. 객체가 생성될 때마다 새로운 값이 할당됩니다.
- 인스턴스 변수는 객체가 생성될 때 메모리에 할당되는 변수입니다.
- 각 객체가 고유하게 가지는 변수로, 다른 객체와 독립적으로 동작합니다.
- 인스턴스 변수는 클래스의 멤버 변수 중 static이 아닌 변수를 의미합니다.
- 예: private String name;은 인스턴스 변수로, 인스턴스마다 다른 이름을 가질 수 있습니다.
- 클래스 변수는 클래스 자체에 속하며, 모든 객체가 공유하는 변수입니다.
- static 키워드를 사용해서 선언되며, 프로그램 실행 시 메모리에 한 번 할당됩니다.
- 클래스 변수는 객체를 생성하지 않고도 접근할 수 있습니다.
- 예: ClassName.variableName으로 접근.
- 지역 변수는 메서드나 생성자 내부에서 선언된 변수입니다.
- 해당 메서드나 생성자가 실행되는 동안만 사용되며, 그 이후에는 메모리에서 사라집니다.
- 클래스나 인스턴스와는 무관하게, 메서드 내에서만 사용되는 변수입니다.
- 메서드나 생성자에 인자로 전달된 변수들입니다. 메서드 호출 시 넘겨받은 값들을 저장하는 데 사용됩니다.
- 멤버 변수는 클래스에 속하는 변수로, 클래스 변수와 인스턴스 변수로 나눌 수 있습니다.
- 인스턴스 변수는 객체마다 개별로 존재하는 변수이며, 클래스 변수는 클래스 전체에서 공유되는 변수입니다.
- 이 외에도 메서드 내부에서 선언되는 지역 변수와 메서드 호출 시 전달되는 파라미터 변수가 있습니다.
- 클래스 내에서 사용되는 변수와 메서드에 대한 개념을 명확히 구분해 보면, 각 변수가 어떻게 사용되는지 쉽게 이해할 수 있을 거예요.
메서드

(접근제어자) (반환값의 자료형) 메서드명 (매개변수 자료형, 매개변수 명..)
public int add (int num1, int num2) {
int result;
result = num1 + num2; // 명령어
return result; // 리턴값(=반환값) (자료형은 int)
}
- 반환 값은 리턴 값이라고도 부른다.
- return 다음에 오는 것(반환값, result)의 자료형(int)이 메서드명(add) 앞에 와야한다.
- 위에서 파라미터는 int num1, int num2 이다.

- 반환값이 없다는 것은 return 값이 없다는 것이므로 메서드명 앞에 특정 자료형이 아니라 반드시 void 를 붙여준다.
- 리턴 값이 없으면 ⇒ 메서드명 앞에 void 붙이기
- 리턴 값이 있으면 ⇒ 메서드명 앞에 리턴값의 데이터 타입 명시
- 파라미터가 있다면 받아올 파라미터를 각각 데이터 타입과 변수명을 적는다.
- 파라미터가 없으면 빈 괄호로 두면 된다.
method1 : 메서드 개요
public class method1 {
public static void main(String[] args) {
// 1~10 합
int sum = 0;
for (int i = 1; i <= 10; i++) {
sum += i;
}
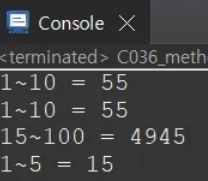
System.out.println("1~10 = " + sum); // 55
// 메서드 호출 부분 calcSum(파라미터1, 파라미터2)
// 파라미터가 없어도 소괄호( )는 붙어야한다.
System.out.println("1~10 = " + calcSum(1, 10)); // 55
System.out.println("15~100 = " + calcSum(15, 100)); // 4945
// 리턴값이 있다면,
// 리턴값의 데이터 타입과 동일한 변수를 만들어서
// 변수 안에 할당할 수도 있다. void는 불가능
int oneToFive = calcSum(1, 5);
System.out.println("1~5 = " + oneToFive); // 15
}
// 내가 입력하는 숫자부터 입력하는 숫자까지의 합을 구하는
// method를 만들어서 활용하자.
// 메서드 정의 부분
//(접근제어자) (리턴값 자료형) (메서드명) (파라미터 타입 및 파라미터명)
public static int calcSum(int from, int to) {
int sum = 0;
for (int i = from; i <= to; i++) {
sum += i;
}
return sum; // 리턴값의 데이터 타입은 int
}
}
calcSum 로직
- 호출하는 메서드의 파라미터의 갯수와 데이터타입에 맞게 호출할 때 정확히 넣어야한다.
- calcSum(1, 10) : from 에는 1 을, to 에는 10 을 입력하고 calcSum 메서드를 호출한다.
- calcSum 이 호출되면 대기하고 있던 calcSum 메서드 내부로 넘어간다. (calcSum 공간이 생성됨)
- 내부 로직이 실행된다.
- 1부터 10까지 반복문이 실행되면서 sum에 누적으로 합해진다.
- 반복문이 종료되면 다음 코드인 return sum 에 의해서 sum 변수 안의 정수형 타입의 55가 반환된다.
- calcSum 메서드 종료. (calcSum 공간이 사라짐)
- 그래서 곧 calcSum(1, 10) ⇒ 55 가 되는 것.
method2 : 메서드의 종류
public class method2 {
/*
* 메서드 생성 부분 (정의 부분)
* 접근지정자 ( ) 리턴 타입 메서드명 ( 데이터타입 매개변수1, ... ) {
* 실행하려는 명령어...;
* return 반환할 값;
* // 반환값의 데이터 타입과 리턴 타입은 동일해야 함
* }
*/
// method2 클래스의 main 메서드
public static void main(String[] args) {
// 1번. 파라미터 X, 반환값 X
method1();
// 2번. 파라미터 X, 반환값 O
// 반환값을 받아줄 변수 result
// 받아주는 result 또한 반환값의 데이터 타입을 동일하게 해야한다.
String result = method2();
System.out.println(result);
// 3번. 파라미터 O, 반환값 X
// 메서드 내의 파라미터의 데이터 타입과 동일한
// input 값을 줘야한다.
method3(333);
// 4번. 파라미터 O, 반환값 O
method4(1, 5); // 6을 반환하지만 받을 곳이 없다.
int sum = method4(2, 3);
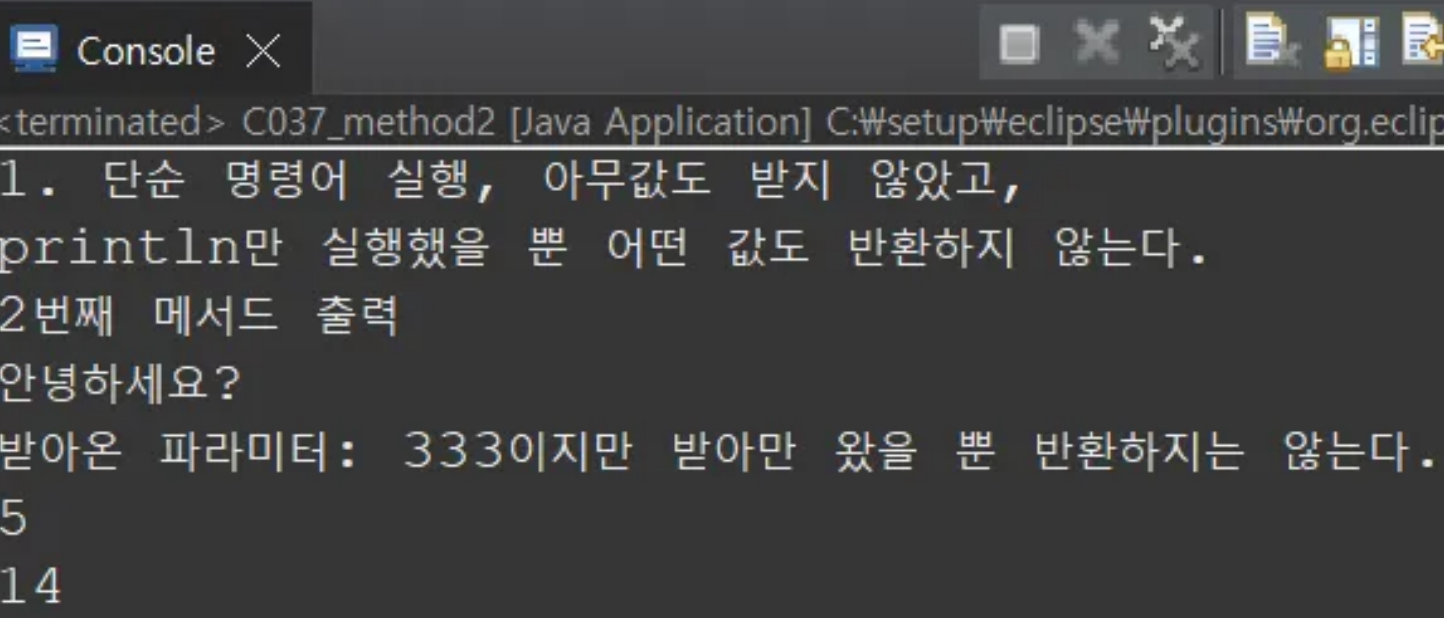
System.out.println(sum);
System.out.println(method4(5, 9));
}
// 1. 데이터를 받아오지도, 데이터를 반환하지도 않는 메서드
// 파라미터 X, 반환값 X
// 파라미터 없으니까 void 사용
// 호출하면 실행만 할 뿐...
// 반환할 값이 없더라도 return; 만은 사용 가능.
public static void method1( ) {
System.out.println("1. 단순 명령어 실행, 아무값도 받지 않았고,\\n"
+ "println만 실행했을 뿐 어떤 값도 반환하지 않는다.");
return; // 메서드를 호출한 곳으로 돌아가라!! = 메서드를 종료한다.
// return; 은 생략 가능
}
// 2. 데이터를 받아오지는 않지만, 데이터를 반환하는 메서드
// 파라미터 X, 반환값 O
public static String method2() {
System.out.println("2번째 메서드 출력");
String result = "안녕하세요?";
return result;
// return 값을 작성하지 않으면
// String 타입의 데이터를 반환하라는 오류가 뜬다.
}
// 3. 데이터를 받아오지만, 데이터를 반환하지 않는 메서드
// 파라미터 O, 반환값 X
public static void method3(int a) {
System.out.println("받아온 파라미터: " + a
+ "이지만 받아만 왔을 뿐 반환하지는 않는다.");
}
// 4. 데이터를 받아오기도, 데이터를 반환하기도 하는 메서드
// 파라미터 O, 반환값 O
public static int method4(int a, int b) {
int sum = a + b;
return sum;
}
}
Return은 왜 다른 코드 위에 있으면 안되나요??
- return 코드를 만나면 메서드는 종료되어 return 아래의 코드는 실행되지 않습니다.
- 그래서 Java 자체에서 컴파일할 때, 실행되지 않는 코드가 있으면 unreachable code 라는 오류를 띄웁니다.
- 설명 및 이유:
- 메서드의 종료: return은 메서드의 결과를 반환하면서 즉시 메서드를 종료합니다. 즉, return 이후에 있는 코드는 더 이상 실행되지 않습니다. 만약 return이 메서드 중간에 있으면, 그 이후의 코드는 사실상 의미가 없고 쓸모가 없어집니다.
위 코드에서는 return 문이 먼저 나와서, 그 뒤에 있는 System.out.println 문은 절대 실행되지 않습니다.public int addNumbers(int a, int b) { return a + b; // 메서드는 여기서 끝남. System.out.println("This will never print."); // 이 코드는 실행되지 않음. } - 예시:
- 논리적 흐름의 왜곡: 메서드 안의 코드는 일반적으로 논리적인 흐름을 따릅니다. return 문을 중간에 넣으면, 코드를 읽는 사람이 "왜 중간에서 메서드가 끝나는지" 의문을 가질 수 있습니다. 이를 잘못 사용하면 코드를 이해하기 어렵게 만듭니다.
- 예상치 못한 결과: 만약 return을 너무 일찍 쓰면, 메서드가 아직 수행해야 할 작업을 마치지 못하고 종료될 수 있습니다. 이런 경우 결과가 잘못될 가능성이 큽니다.
위 코드에서 x가 음수일 때 바로 메서드를 종료하게 되는데, 이 경우 이후의 x * 2 같은 처리가 전혀 이루어지지 않습니다. 논리적 흐름에 맞지 않는 return은 이렇게 문제가 발생할 수 있습니다.public int calculate(int x) { if (x < 0) { return -1; // 여기서 메서드가 종료됨 } x = x * 2; // 이 코드는 x가 0 이상일 때만 실행됨 return x; } - 예시:
- 정상적인 결과를 반환할 때: 메서드가 해야 할 작업을 모두 마치고, 그 결과를 반환할 때 사용됩니다.
- 특정 조건에 따른 조기 종료: 메서드가 어떤 조건에서 더 이상 실행할 필요가 없을 때 사용할 수 있습니다. 예를 들어, 잘못된 입력이나 에러 처리 같은 상황에서 메서드를 조기 종료하는 경우입니다.
public int divide(int a, int b) { if (b == 0) { return -1; // b가 0일 경우 나눗셈을 진행하지 않고 메서드를 종료 } return a / b; // 정상적인 나눗셈 결과 반환 } - 예시:
- 메서드의 종료: return은 메서드의 결과를 반환하면서 즉시 메서드를 종료합니다. 즉, return 이후에 있는 코드는 더 이상 실행되지 않습니다. 만약 return이 메서드 중간에 있으면, 그 이후의 코드는 사실상 의미가 없고 쓸모가 없어집니다.
- 메서드 안에서 return 문을 사용하면 그 메서드는 즉시 종료되기 때문에, return 이후에 위치한 코드는 실행되지 않습니다. 따라서 return을 중간이나 다른 코드보다 위에 작성하면, 그 아래에 있는 코드는 아예 실행되지 않고 무시됩니다. 이를 통해 여러 가지 문제가 발생할 수 있습니다.
method3 : 날짜 추출 메서드 만들기
public class method3 {
public static void main(String[] args) {
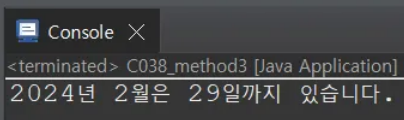
int year = 2024;
int month = 2;
int days = getMonthDays(year, month);
System.out.println(year + "년 " + month + "월은 " + days + "일까지 있습니다.");
}
public static int getMonthDays(int year, int month) {
// int[] : 정수형 타입의 데이터가 들어가는 배열
// 월별 마지막 날짜가 들어가있다.
// 배열은 0번부터 시작한다.
// 0번 방: 0, 1번 방: 31, 2번 방: 28 ....
// 그래서 1번 인덱스(1번 방)의 31은 1월에 해당하는 31일이라고 볼 수 있게 된다.
int[] arDays = {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
// 2월 일 경우
if (month == 2) {
// 윤년 검사 : 윤년이면 29일 반환
// 윤년이 여기서 전부 걸러짐
if (year % 4 == 0 && year % 100 != 0 || year % 400 == 0) {
return 29;
}
// 윤년이 아닌 2월이면 28일 반환
// 위에서 윤년을 전부 거르고 남은 2월만 남음
return 28;
} else {
// if 절에서 모든 2월이 전부 걸러짐
// 2월이 아니면 배열 인덱스에 맞춰 월별 마지막 날짜 반환
return arDays[month];
}
}
}
Java에도 && 와 || 의 우선순위가 있나요?
- 요약 : Java도 SQL 처럼 && 가 || 보다 우선순위가 높다!!
- 우선순위 설명
- && (AND) 연산자는 || (OR) 연산자보다 우선순위가 높습니다.
- 즉, Java에서는 && 연산이 먼저 수행되고, 그다음에 || 연산이 처리됩니다.
- 먼저, && 연산이 먼저 수행됩니다.이 부분은 윤년을 계산하는 첫 번째 조건입니다. 즉, 연도가 4로 나눠떨어지지만, 100으로 나눠떨어지지 않는 경우를 의미합니다.
- (year % 4 == 0 && year % 100 != 0)
- 그런 다음, || 연산이 처리됩니다.이제 두 번째 조건인 year % 400 == 0이 추가됩니다. 이 조건은 연도가 400으로 나눠떨어지면 윤년이 되는 경우를 의미합니다.
- (year % 4 == 0 && year % 100 != 0) || (year % 400 == 0)
- 먼저 **year % 4 == 0 && year % 100 != 0*이 계산된 후,
- 그 결과와 **year % 400 == 0*이 || (OR) 연산으로 결합됩니다.
method4 : 날짜 추출 메서드
import java.time.LocalDate;
public class method4 {
public static void main(String[] args) {
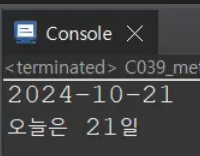
// getDate 메서드로부터 반환된 21이 나온다.
System.out.println("오늘은 " + getDate() + "일");
}
public static int getDate() {
// java.time 패키지 안에는 날짜와 시간을 다룰 수 있는 다양한 클래스가 있는데,
// 그중 LocalDate 클래스는 날짜(년, 월, 일)를 처리하는 클래스다.
// LocalDate의 now() 메서드는 현재 날짜를 가져온다.
LocalDate today = LocalDate.now(); // 현재 날짜를 today 변수에 저장 (예: 2024-10-21)
System.out.println(today); // 2024-10-21
// now() 메서드를 통해 가져온 today 객체에서 날짜(일)를 얻기 위해 getDayOfMonth()를 사용한다.
// 이 메서드는 년-월-일에서 일(day) 값을 반환한다.
int day = today.getDayOfMonth(); // 예: 21
return day; // 얻은 날짜(21)를 반환
}
}
method_valueCheck : 기본형 데이터와 참조형 데이터의 변경 차이
public class method_valueCheck {
public static void main(String[] args) {
// 1. num 변수에 2가 할당됨 (기본 타입은 stack 메모리 영역에 저장됨)
int num = 2;
// getDouble(num) 메서드가 호출되었지만, 반환된 값(4)을 받는 변수가 없음
// 기본 타입인 int는 stack 영역에서 처리되므로, 메서드 내부에서 값이 복사되어 전달됨
getDouble(num);
// 메서드에서 num의 값을 변경해도 stack 영역에 있는 num의 실제 값은 변경되지 않음
// 따라서 num의 값은 여전히 2가 유지됨
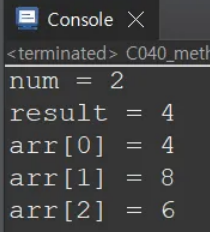
System.out.println("num = " + num); // 출력: num = 2
// getDouble(num) 메서드가 반환한 4를 result 변수에 저장
// 이제 반환된 값을 저장할 변수가 있기 때문에 값이 유지됨
int result = getDouble(num);
// result 변수에 저장된 값을 출력 (4가 출력됨)
System.out.println("result = " + result); // 출력: result = 4
// 2. 배열 arr에 {2, 8, 6}이 초기화됨
// 배열은 참조 타입이므로 heap 메모리 영역에 저장됨
// arr 변수는 stack 영역에 저장된 참조(주소 값)을 가지고 있으며, 실제 배열 데이터는 heap에 있음
int[] arr = { 2, 8, 6 };
// getDouble(arr) 메서드는 배열의 첫 번째 요소를 2배로 변경함
// 참조 타입인 배열은 heap에 저장된 데이터를 참조하므로, 메서드에서 변경이 발생하면 원본 배열도 변경됨
getDouble(arr);
// 배열을 순회하면서 값들을 출력
// 첫 번째 요소(0번 인덱스)가 2에서 4로 변경됨
// 따라서 출력은 [4, 8, 6]이 됨
for (int i = 0; i < arr.length; i++) {
System.out.println("arr[" + i + "] = " + arr[i]);
}
}
// 기본 타입(int)을 받아서 값을 2배로 하고, 그 값을 반환하는 메서드
public static int getDouble(int value) {
// 전달된 value는 stack 영역에서 복사된 값으로 전달됨
// 여기서 value는 메서드가 호출될 때 stack에 새롭게 생성된 지역 변수
// value에 2를 곱함, 이제 value는 4가 됨
value *= 2;
// 4를 반환, 하지만 호출한 곳에서 받지 않으면 값은 버려짐
return value;
}
// 배열을 받아 첫 번째 요소를 2배로 변경하는 메서드
public static void getDouble(int[] value) {
// value 배열의 첫 번째 요소인 0번 인덱스에 있는 값을 2배로 함
// 배열은 참조 타입이므로, value는 heap에 있는 배열 데이터를 참조
// 즉, 메서드 내에서 배열의 값이 실제로 변경됨
value[0] *= 2;
}
}
- 상세설명
- Stack 영역 (스택 메모리):
- 기본 타입 변수(예: int num)는 stack 메모리에 저장됩니다.
- stack은 함수 호출 시마다 메모리를 할당하고, 함수가 끝나면 메모리를 자동으로 해제하는 후입선출(LIFO, Last In First Out) 구조입니다.
- getDouble(num) 메서드 호출 시, num의 값인 2가 stack에 복사되어 전달됩니다. 따라서 메서드 내부에서 value라는 새로운 변수가 생기고, 이 변수의 값만 변경되며, 원래의 num은 변하지 않습니다.
- num은 stack 영역에 저장되며, 메서드가 종료되면 value 변수는 사라집니다. 따라서 메서드 외부에서 num의 값은 여전히 2로 남아있습니다.
- Heap 영역 (힙 메모리):
- 배열이나 객체와 같은 참조 타입은 heap 메모리에 저장됩니다.
- heap은 메모리가 동적으로 할당되는 영역이며, 참조 타입의 데이터는 heap에 실제 데이터(실제 배열 내용)가 저장되고, **stack 영역에는 그 데이터의 주소(배열의 주소값, 참조 값)**가 저장됩니다.
- int[] arr = {2, 8, 6};는 배열의 실제 데이터인 {2, 8, 6}이 heap에 저장되고, arr은 stack에 heap 주소를 저장하여 이를 참조합니다.
- getDouble(arr) 메서드가 호출되면, heap에 있는 배열의 값을 직접 수정할 수 있습니다. 메서드 내부에서 배열의 첫 번째 값이 2에서 4로 변경되고, 이 변경은 배열의 실제 데이터에 적용됩니다. 따라서 배열의 첫 번째 값은 4로 변경됩니다.
- 기본 타입 변수(예: int)는 stack 메모리에서 값이 복사되어 전달되므로, 메서드 내부에서 변경이 이루어져도 원래 변수는 변경되지 않습니다.
- 참조 타입 변수(예: 배열)는 heap 메모리에 저장된 실제 데이터를 참조하므로, 메서드에서 값을 변경하면 원래 데이터도 변경됩니다.
- Stack 영역 (스택 메모리):
왜 어떤 건 바뀐 값이 영향을 주고, 어떤 건 그대로 인가요?
- int 같은 기본 데이터 타입이므로 값 자체가 복사되어 전달되며, 메서드에서 변경해도 원래 값에는 영향을 주지 않습니다.
- 배열 은 참조 타입이므로 Heap 영역에서 생성되므로 주소를 주고 받으며, 메서드에서 배열의 값을 변경할 수 있습니다.
- GPT 설명이유 설명Java에서 기본 데이터 타입(예: int, double, char 등)은 값에 의한 전달로 처리됩니다. 즉, 메서드에 값을 전달할 때 그 값의 복사본이 전달됩니다. 따라서 원래 변수는 영향을 받지 않습니다.
- getDouble(num) 메서드가 호출될 때, num의 값인 2가 메서드에 복사되어 전달됩니다.
- 메서드 내부에서는 value라는 지역 변수가 생성되고, 이 변수는 전달받은 2라는 값을 가지고 있습니다.
- value *= 2가 실행되면서 value는 4가 되지만, 이 변화는 지역 변수에만 적용됩니다. 즉, 원래의 num 변수에는 영향을 미치지 않습니다.
- 따라서 System.out.println("num = " + num);은 여전히 num = 2를 출력합니다.
int[] arr = { 2, 8, 6 }; getDouble(arr); // arr[0] 값은 4로 변경- getDouble(arr)가 호출될 때, 배열 arr의 참조(주소 값)가 복사되어 전달됩니다.
- 이 경우 메서드 내부에서 배열의 첫 번째 요소 arr[0]를 수정하면, 원래 배열 arr의 값도 함께 수정됩니다.
- value[0] *= 2;가 실행되어 배열의 첫 번째 값이 4로 변경됩니다.
- 따라서 배열 arr의 첫 번째 값은 2에서 4로 변경되며, 출력 결과는 arr[0] = 4가 됩니다.
- num은 기본 타입 int로, 값에 의한 전달로 메서드에 전달되므로 num의 원래 값은 변경되지 않습니다.
- arr은 참조 타입이므로 배열의 참조가 전달되어 메서드에서 배열 요소를 변경할 수 있습니다.
- num은 기본 타입이므로 값이 복사되어 전달되며, 메서드에서 변경해도 원래 값에는 영향을 주지 않습니다. 따라서 출력 결과는 num = 2입니다.
- arr은 참조 타입이므로 메서드에서 배열의 값을 변경할 수 있습니다.
- 반면에 배열과 같은 참조 타입은 값에 의한 전달로 참조 자체가 복사됩니다. 즉, 배열의 주소 값이 복사되어 전달되므로, 배열의 실제 값은 메서드에서 변경될 수 있습니다.
- int num = 2; getDouble(num); // num 값은 그대로 2
- 1. 값에 의한 전달 (Primitive Types)
- 이 질문은 값에 의한 전달(pass by value)과 참조에 의한 전달(pass by reference)에 대한 개념을 다루고 있습니다. Java에서는 모든 데이터가 값에 의한 전달로 처리됩니다. 이로 인해 num 변수의 값이 변경되지 않는 이유를 설명할 수 있습니다.
메서드 오버로딩
개요
- 메서드 오버로딩(overloading) 이란 같은 이름의 메소드를 중복하여 정의하는 것
- 오버로딩 조건
- 메서드의 이름이 같아야 한다.
- 파라미터의 개수가 달라야 한다.
- 파라미터의 데이터 타입이 달라야 한다.
- 파라미터의 순서가 달라야 한다.ㄴ
- println 를 생각하면 좋다.
- 같은 메서드 이름인 println 이지만, 들어가는 파라미터의 데이터 타입, 갯수, 순서가 달라지면 overloading 했다고 표현한다.
메서드 오버로딩의 장점

- 다형성 : 한 개가 여러가지 형태를 띈다. 이름은 하나지만 여러개의 메서드로 존재할 수 있다. ex) println
overloading : 메서드 오버로딩 4가지 조건
public class overloading {
public static void main(String[] args) {
/*
* 오버로딩(Overloading) - ex) print, println 메서드
* 하나의 이름으로 여러 처리를 한다. (다형성)
* 1. 메서드의 이름이 같아야 한다. (필수)
* 2. 파라미터 개수가 달라야 한다.
* 3. 파라미터 타입이 달라야 한다.
* 4. 파라미터 순서가 달라야 한다.
*/
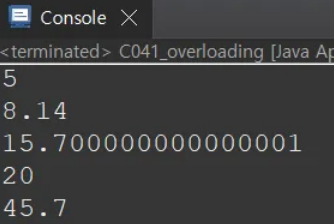
getMax(5); // 5
getMax(5, 3.14); // 8.14
getMax(3.14, 5); // 15.700000000000001
System.out.println(getMax(10, 20)); // 20
System.out.println(getMax(10.5, 45.7)); // 45.7
}
public static void getMax(int a) {
System.out.println(a); // 5
}
// 같은 메서드명인데 같은 파라미터 갯수, 타입, 순서면 오류가 발생
// public static void getMax(int b) {
//
// }
// 파라미터 개수 차이
public static void getMax(int a, double b) {
System.out.println(a + b); // 8.14
}
// 파라미터 순서 차이
public static void getMax(double a, int b) {
System.out.println(a * b); // 15.700000000000001
}
// 파라미터 타입 차이
public static int getMax(int a, int b) {
if (a > b)
return a;
else
return b;
}
public static double getMax(double a, double b) {
if (a > b)
return a;
else
return b;
}
}
왜 double 3.14 와 int 5 를 곱하면 15.7 이 아니라 15.700000001이 나오나요?
- 부동소숫점 연산의 정밀도 한계 때문
- GPT 설명문제 원인:예시 코드:여기서 a = 3.14와 b = 5라고 가정할 경우:
- 3.14 * 5 = 15.7이 나오기를 기대하지만, 이진수로 3.14를 정확하게 표현할 수 없기 때문에 약간의 오차가 발생합니다.
- 이 오차는 부동소수점 연산의 특성상 발생하며, 이는 거의 모든 프로그래밍 언어에서 나타나는 문제입니다.
- printf 사용 (Java에서 소수점 자리수 제한)
- 소수점 자릿수를 명시적으로 지정하여 출력할 수 있습니다.
public static void getMax(double a, int b) { System.out.printf("%.1f\\\\n", a * b); // 출력: 15.7 } - BigDecimal 클래스 사용
- BigDecimal은 정확한 소수점 연산을 위해 사용하는 Java 클래스입니다. 부동소수점 연산의 오차를 해결하고 싶다면, 이 클래스를 사용하는 것이 좋습니다.
import java.math.BigDecimal; public static void getMax(double a, int b) { BigDecimal result = new BigDecimal(a).multiply(new BigDecimal(b)); System.out.println(result); // 정확한 값 출력 } - Math.round() 함수 사용
- 소수점 이하 자릿수를 반올림해서 원하는 자릿수로 맞출 수 있습니다.
public static void getMax(double a, int b) { System.out.println(Math.round(a * b * 10) / 10.0); // 출력: 15.7 }
- 15.700000000000001과 같은 값은 부동소수점 연산의 정밀도 한계 때문에 발생하는 문제입니다. 이 문제를 해결하려면 출력 시 소수점 자릿수를 제한하거나 BigDecimal 같은 클래스를 사용하여 더 높은 정밀도로 연산을 처리할 수 있습니다.
- 이 문제를 해결하기 위해서는 소수점 자리수를 제한하거나 반올림을 통해 원하는 출력 형식을 맞추면 됩니다.
- public static void getMax(double a, int b) { System.out.println(a * b); // 15.700000000000001 }
- double 타입은 이진수로 실수 값을 표현하기 때문에, 소수점 값의 정확한 표현이 어려운 경우가 있습니다. 15.7이라는 값은 이진수로 완벽하게 표현되지 않기 때문에 15.700000000000001 같은 값으로 출력됩니다.
- 이 문제는 부동소수점(Floating Point) 연산에 의한 정밀도 문제 때문입니다. Java에서 double 타입은 64비트로 저장되며, 이는 소수점 이하의 값을 정확하게 표현할 수 없는 경우가 있습니다. 특히 이진수로 소수점 숫자를 표현할 때 완벽한 표현이 불가능한 경우가 종종 발생합니다. 이러한 이유로, 일부 소수점 값이 우리가 예상한 것보다 더 길게 나오거나 정확하지 않은 결과를 나타낼 수 있습니다.
Method_Example : 구구단 출력 (1. Math.random() 사용 / 2. method 내 method 구현)
import java.util.Scanner;
public class Method_Example {
public static void main(String[] args) {
// 전체 구구단을 출력하는 메서드 작성
// 메서드 호출
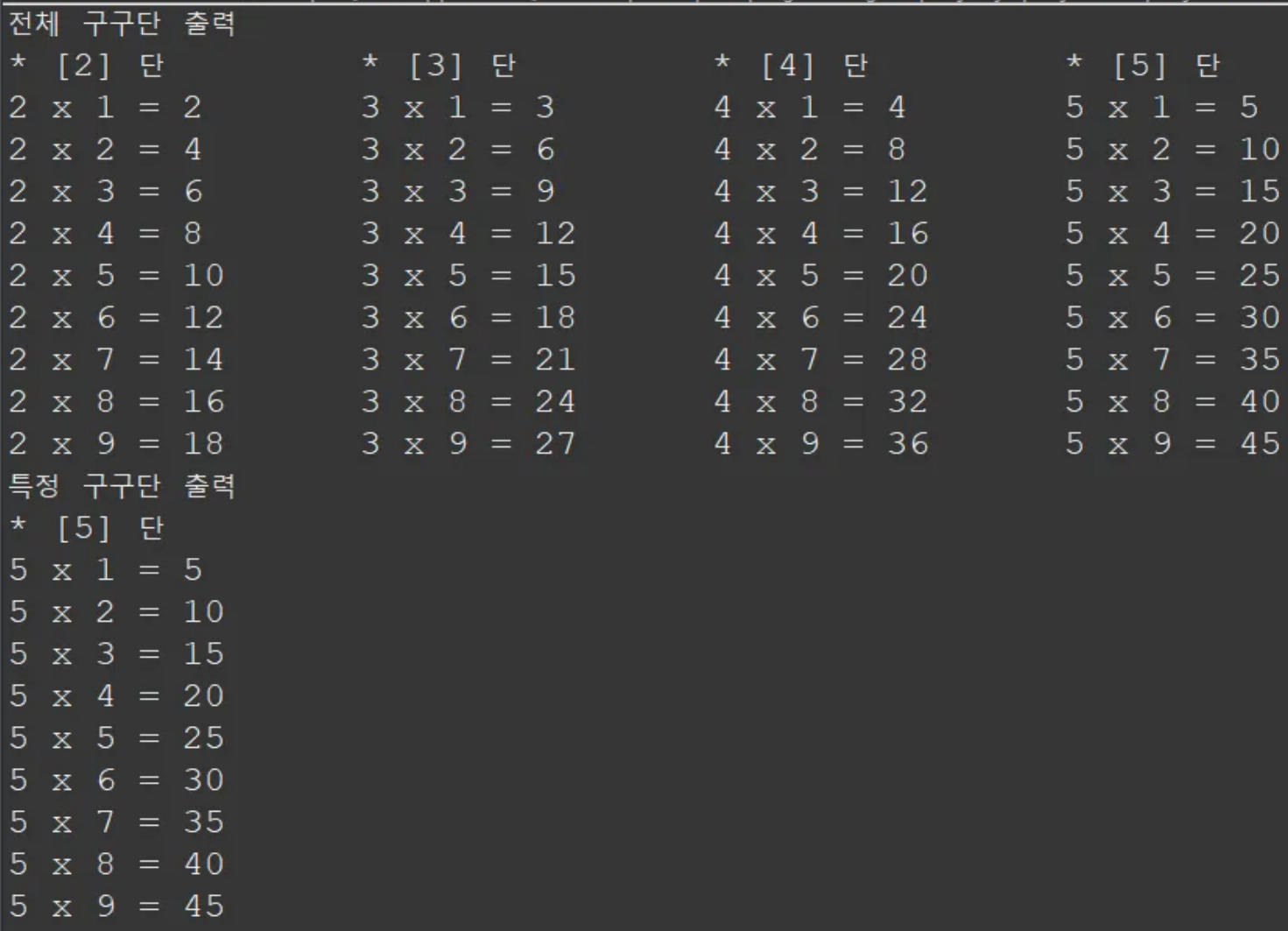
System.out.println("전체 구구단 출력");
gugudan();
// 특정 구구단 출력
System.out.println("특정 구구단 출력");
// num 을 0 또는 1이 아닐 때까지 while 반복문 진행
int num = 0;
while (true) {
num = (int) (Math.random() * 10);
if (num != 0 && num != 1)
break;
}
gugudan(num);
// 전체 구구단 출력
methodEx();
System.out.println("============");
// 특정단 출력
Scanner sc = new Scanner(System.in);
System.out.print("단: ");
methodEx(sc.nextInt());
sc.close();
}
// 메서드 정의
public static void gugudan() {
for (int i = 2; i <= 9; i++) {
System.out.print("* [" + i + "] 단 \\t");
}
System.out.println();
for (int i = 1; i <= 9; i++) {
for (int j = 2; j <= 9; j++) {
System.out.print(j + " x " + i + " = " + (i * j) + "\\t");
}
System.out.println();
}
}
public static void gugudan(int num) {
System.out.println("* [" + num + "] 단");
for (int i = 1; i <= 9; i++) {
System.out.println(num + " x " + i + " = " + (num * i));
}
}
public static void methodEx() {
for (int i = 2; i <= 9; i++) {
System.out.println("* [" + i + "] 단");
methodEx(i);
System.out.println();
}
}
public static void methodEx(int number) {
for (int i = 1; i <= 9; i++) {
System.out.println(number + " x " + i + " = " + (number * i));
}
}
}
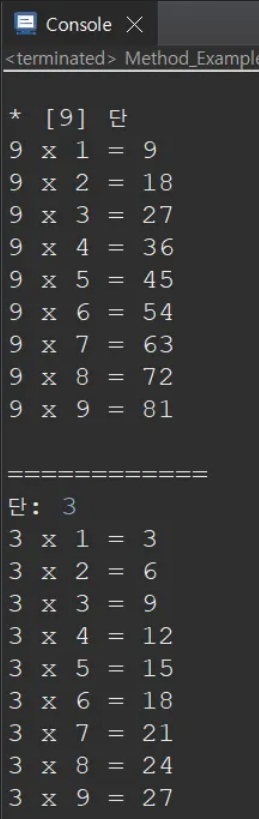
Math.random( )의 범위는 0.0 이상, 1.0 미만 이다.
Math.random()은 0.0 이상 1.0 미만의 double 값을 반환합니다. 즉, 반환되는 값은 0.0을 포함할 수 있지만, 1.0은 포함되지 않습니다.
범위:
- 포함: 0.0 <= Math.random()
- 미포함: Math.random() < 1.0
Math.random()은 [0.0, 1.0) 구간에서 균일한 확률로 임의의 실수를 생성합니다.
Method의 이름을 아낀다는 표현이 무엇인가? (Overloading의 장점)
- 그냥 메서드를 계속 다르게 만들면 되는데 굳이 overloading을 해서 메서드 명을 같이하는게 무엇이 장점일까?
- double 타입의 합을 구하는 메서드와 int 타입의 합을 구하는 메서드가 있다고 할 때, sumDouble , sumInt 로 계속 만들 수도 있다. 하지만 내부 로직은 더하는 것으로 같으므로 아래와 같이 할 수 있다.
public static int sum(int a, int b){
int sum = a + b;
return sum;
}
public static double sum(double a, double b){
double sum = a + b;
return sum;
}
- 이런 합을 구하는 메서드가 1000개가 있다고 하면, sum 뒤에 계속 타입마다 모두 다르게 붙여야하는데, overloading을 하면 sum 이라는 하나의 메서드 이름으로 사용 가능해진다. 메서드명을 고민하지 않아도 된다!
728x90
반응형